
Let’s embark on a tale back to the era of yore, when smartphones not yet ruled the earth, Pentiums were king, and Intel believed that x86 had no future.
I wasn’t much into technology at the time Itanium came out, so I only properly heard of it years later. Sometime in late 2021, I was introduced to Raymond Chens Old New Thing article series on the subject. I was instantly hooked. In March 2022, I started a thorough investigation of what I could accomplish with this knowledge.
If You Were Around When Itanium Was A Thing
Please skip to the end of this article and read the section “Stay Tuned”, and keep it in mind as you read this article.
Anything you can do, I can do more of (at the same time)
There are two ways to make a series of sequential tasks faster– do each one quicker, or do multiple in parallel. Operations continue to get faster and faster (by way of clock speed increases and general optimizations), but if you have a string of instructions, how do you make them work in parallel?

Todays computers do what’s called Out of Order/Superscalar execution. The idea is, most execution streams that appear linear aren’t necessarily dependent on each other. You might notice that the calculation of e and f aren’t actually dependent on each other– you load a and b to calculate e, and c and d to calculate f. So that’s what modern computers do– they look ahead in the instruction stream and figure out what needs to be done, then analyze data dependencies, re-order the independent instructions, and finally execute those independent streams in parallel.
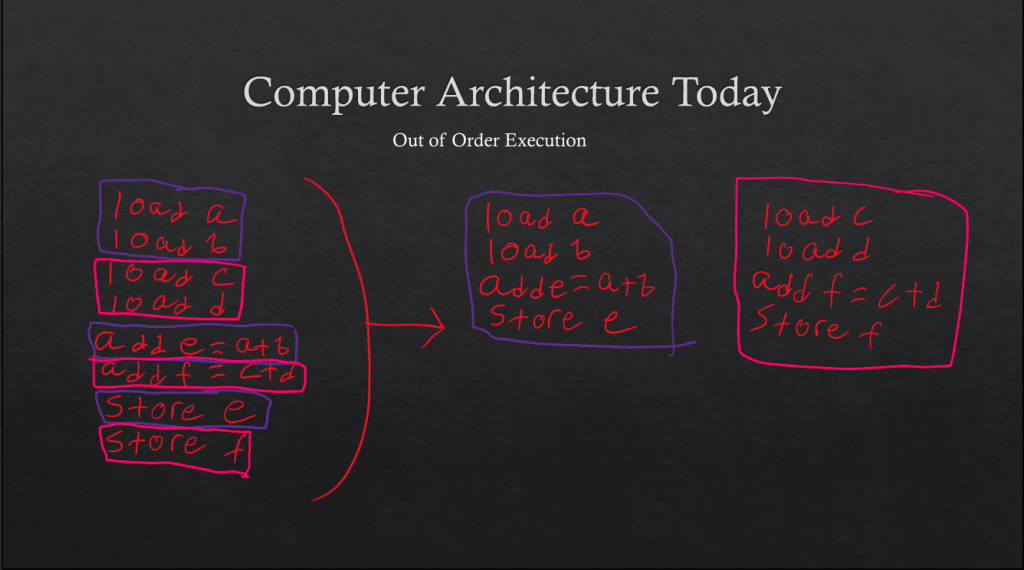
Sound complicated? That’s because it is. These principles work, but they didn’t exist at all in the 90s, when Itanium was being developed. At the time, Intel had a very different idea of what parallel execution would look like…

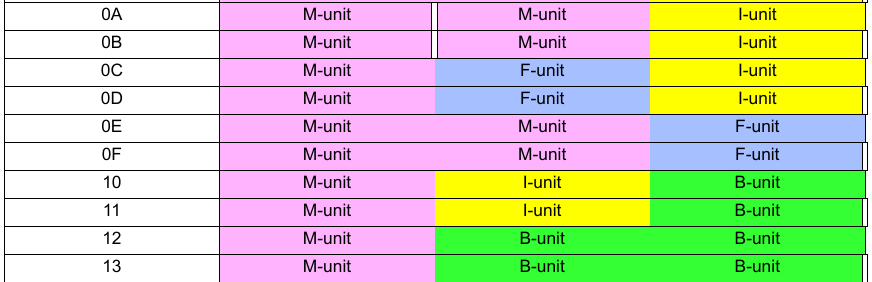
Instructions of Itanium are always grouped into blocks of three, called “bundles”. Each bundle has a “template” that defines what each instruction in the bundle looks like (for example, MII means the bundle has one Memory instruction and two Integer instructions.) Bundles are executed in parallel, unless the bundle encodes a “stop” (denoted as ;;) which denotes that the next instruction in the bundle is dependent on the previous instructions in the bundle. As long as no stops are present, the CPU can continue dispatching bundles in parallel, making a fully parallelized “instruction group”. For instance, the original Itanium 2 can dispatch up to six instructions (two bundles) in parallel if there are no stops.

Notice that this is much less work for the silicon of the device. The compiler is the entity responsible for generating parallelism. So instead of carefully analyzing and tracking instructions while they’re in flight, the CPU just has to do dumb execution of the program, knowing that it’s getting massive speedups by executing code in parallel!
Now I must point out that Itanium and its ideas were a failure. This should be obvious, given that it required significant introduction. It struggled to take off in the server space early on, then AMDs 64-bit extensions to x86 killed off any remaining chance of success it had. More importantly, however, the fundamental idea of Itanium– parallel instruction decoding– does not work. There are two main reasons for this:
- It’s not always possible to fit instructions into groupings of three. Notice that the code I wrote above, which simply calculates two numbers, had to have “no-ops” inserted to make a complete bundle. That’s both because dependencies between instructions had to be accounted for, and because the number of templates is very limited (there are only 32) so even if parallelism could be present it may not always be possible to encode it as such. Compare this to other architectures, which have none of these limitations– just write instructions and you’re set.If it seems that this is a contrived example meant to forcibly showcase the issue, let’s take a look at the first instructions found in an
objdumpof libc:
000000000002e580 <.plt>:
2e580: 0b 10 00 1c 00 21 [MMI] mov r2=r14;;
2e586: e0 60 28 63 4a 00 addl r14=1218700,r2
2e58c: 00 00 04 00 nop.i 0x0;;
2e590: 0b 80 20 1c 18 14 [MMI] ld8 r16=[r14],8;;
2e596: 10 41 38 30 28 00 ld8 r17=[r14],8
2e59c: 00 00 04 00 nop.i 0x0;;
2e5a0: 11 08 00 1c 18 10 [MIB] ld8 r1=[r14]
2e5a6: 60 88 04 80 03 00 mov b6=r17
2e5ac: 60 00 80 00 br.few b6;;
2e5b0: 11 78 00 00 00 24 [MIB] mov r15=0
2e5b6: 00 00 00 02 00 00 nop.i 0x0
2e5bc: d0 ff ff 48 br.few 2e580 <__h_errno@@GLIBC_PRIVATE+0x2e50c>;;
2e5c0: 11 78 04 00 00 24 [MIB] mov r15=1
2e5c6: 00 00 00 02 00 00 nop.i 0x0
2e5cc: c0 ff ff 48 br.few 2e580 <__h_errno@@GLIBC_PRIVATE+0x2e50c>;;- Cache hierarchies. With a multi-core, multi-process, modern operating system computing environment, it’s practically impossible to know how physically close your data is to your execution unit.
- Is it in the L1 cache, which is right next to the execution units?
- Is it in the L2 cache, which is shared by multiple nearby cores?
- Is it in the L3 cache, which is shared by the entire CPU?
- Or is it all the way out in DRAM, which is so slow it might as well be on another planet?
You simply can’t know how long your data accesses will take because the interaction of multiple cores running multiple processes which all need to access data, and a modern OS scheduling those processes based on incredibly detailed minutiae, makes it so that data could be anywhere in that massive hierarchy. Out of Order CPUs can absorb unexpected massive latency by tracking another execution stream where data is ready and executing that instead. The Itanium approach can’t do this. It instead stalls on all execution until one load in a bundle is finished, even if successive bundles don’t depend on that load.
Dredging Up The Itanic
Itanium has been dead and forgotten to most for almost 20 years. Obviously, I need to dig it up and making something cool with it. But what? How about a shellcoding challenge?
If I want to make a shellcoding challenge, I’ll have to spin up an environment where I can develop and run code for Itanium.
This ended up taking longer than actually writing the challenge.
The obvious first step is finding a working Itanium system. After all, The Register wrote an article about finding many hundreds of Itanium CPUs on eBay. This is true! You too can own your very own Itanium CPU for a mere $30 in the U.S. However, that silicon won’t be especially useful without a motherboard to put it in.
It is not currently possible to purchase a standalone Itanium motherboard.
The next step was looking at purchasing blades for an Itanium server. (Itanium primarily targeted the server market.) With a fair amount of effort searching on eBay, it was possible in April 2022 to find an Itanium blade for $300.
Thankfully, before I dropped $300 on one of these things (quite a lot of money for me to spend on anything, let alone a side project) an IT friend who I was discussing this asinine project with pointed out an important issue to me– blades typically use bizarre, proprietary power supply connections and fit into a blade chassis which delivers that power. Without a blade chassis ($1500) I would be purchasing a very heavy and expensive paperweight. Thanks, Travis!
As an aside, it seems that at the time of writing (May 2023) it’s become easier to find those blades at that price or even slightly lower (there’s one at $145 right now.) I’m also seeing a single listing for a complete Itanium 2 server (with a standard power supply jack) that was probably released around 2003 at $425. Either way, this wasn’t the case last year, so I moved on to emulation.
Ski
A resource I stumbled upon early on was Sergei Trofimovich’s post on the Ski emulator, which described how he used it to fix a bug in the kernel. Ski was an emulator developed by HP back when they were building Itanium to test the software they were making on their “legacy” x86 machines. Ski was made in an era when multi-core processors didn’t exist and the Pentium brand name was still the gold standard for quality– so naturally, it’s a little dated. Thankfully, Trofi had managed to get a version working on modern Linux, and Ski is good enough to bring up an entire OS image! I was able to compile and boot it on my Fedora desktop.
The next step was to get a working OS image. I needed something good enough to develop my shellcoding challenge– it needed Vim, GCC and GDB. Trofi suggested cross-compiling Gentoo for this task in his article… But I didn’t have a working knowledge of Gentoo, so I turned to digging through old archives for OS images. I found some CentOS and Debian ISOs, but there was a big problem with them– Ski has no understanding of ISO images. It can only boot a kernel binary with a raw hard disk image attached, so these DVDs aren’t useful. I ended up reaching out to him and got some excellent, highly detailed instructions on how exactly to build the system by creating a Gentoo chroot and setting up environment within it, including some updates for 2022 that would have otherwise caused the finished build to fail to boot. One particular piece of advice is that support for Ski was removed from the kernel in 2019, so we’ll have to build a kernel before that time– 4.19.241 will do.
Out of the box, the image that Gentoo built for me had gcc but no other tooling, so I set out to build the tools myself. Ski is, as to be expected, very slow, and building vim for starters didn’t go so well. On a Zen 2 desktop, I set it to compile… and after six hours attempting to compile a single file it ran out of memory. Attempting to add more memory to the emulated processor made it lock up, and I had no idea why, but it was clear that “native” compilation wasn’t the way to go anyway.
Another friend who had been following along with this story, xxc3nsoredxx was a full-time Gentoo user and was able to within minutes point out to me that one of Gentoos strengths is cross-compilation for obscure architectures. A quick tutorial on emerge later, and I was able to successfully build vim and gdb and run it within Ski.
The complete instructions for how to build a working Itanium environment on Linux can be found here or in the website header..
Stay Tuned
In the second part of this article, I’ll discuss using these newfound tools to create an extremely irritating shellcoding challenge.
A lot of people worked on Itanium, from the original idea of EPIC to its slow and painful death. The biggest, and most surprising, lesson I took away from reconstructing a working development environment in 2023 is that almost all of those stories have been forgotten. I’d find one person talk about supporting Itanium in disused comments sections, old, forgotten documentation that had to be carefully coaxed out of the Internet Archive, and some still-living docs on Intels website… But for all the labor that had to have gone into the Itanic I found little evidence that people worked on this. So if you worked on Itanium, or know someone who did, please reach out and tell me your story in the comments below.