
Man, I should really write a clickbait article about the Switch before the Switch 2 comes out.
– Me
What’s more clickbaity than AI ✨? We’re now in the third year of being promised the world– AI ✨ is going to change everything, everywhere, and if you’re not adopting it into every aspect of your life and career you’re going to get left in the dust.
The Switch runs an off-the-shelf Nvidia Tegra X1 with 4GB of RAM. It was Nvidias second desktop GPU architecture in a mobile chip, after the Nvidia Tegra K1, containing 256 Maxwell CUDA cores. Announced ten years ago now (On January 5, 2015) it was originally intended for tablets and the automotive industry, before Nintendo picked it up. The Jetson TX1 dev kit was released and it was also present in the somewhat popular and well-known Jetson Nano (though with only half the CUDA cores enabled.) A fully functional (albeit largely proprietary, in traditional Nvidia fashion) Linux4Tegra distribution was shipped, with a working CUDA development environment.
CUDA? The compute platform that’s driving the AI revolution ✨? In my Nintendo Switch?
Surely you see where I’m going with this.
Still image version
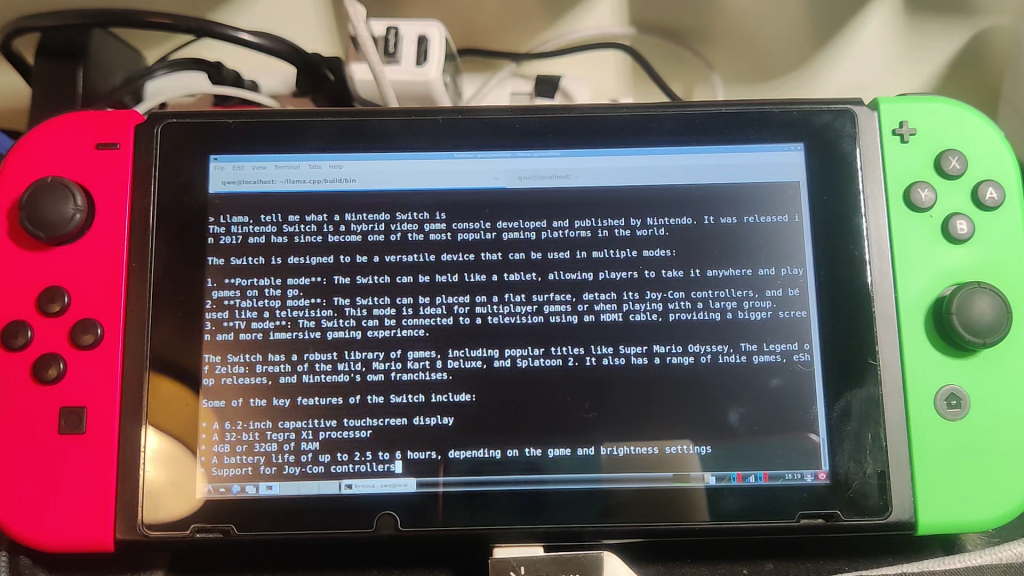
Pure text version
qwe@localhost:~/llama.cpp/build/bin$ ./llama-cli -m ~/Llama-3.2-3B-Instruct-Q4_K_M.gguf -ngl 100 -cnv --chat-template llama3
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA Tegra X1, compute capability 5.3, VMM: no
register_backend: registered backend CUDA (1 devices)
register_device: registered device CUDA0 (NVIDIA Tegra X1)
register_backend: registered backend CPU (1 devices)
register_device: registered device CPU (ARMv8 Processor rev 1 (v8l))
build: 4418 (b56f079e) with gcc (GCC) 8.5.0 for aarch64-unknown-linux-gnu (debug)
main: llama backend init
main: load the model and apply lora adapter, if any
llama_load_model_from_file: using device CUDA0 (NVIDIA Tegra X1) - 2755 MiB free
llama_model_loader: loaded meta data with 35 key-value pairs and 255 tensors from /home/qwe/Llama-3.2-3B-Instruct-Q4_K_M.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Llama 3.2 3B Instruct
llama_model_loader: - kv 3: general.finetune str = Instruct
llama_model_loader: - kv 4: general.basename str = Llama-3.2
llama_model_loader: - kv 5: general.size_label str = 3B
llama_model_loader: - kv 6: general.license str = llama3.2
llama_model_loader: - kv 7: general.tags arr[str,6] = ["facebook", "meta", "pytorch", "llam...
llama_model_loader: - kv 8: general.languages arr[str,8] = ["en", "de", "fr", "it", "pt", "hi", ...
llama_model_loader: - kv 9: llama.block_count u32 = 28
llama_model_loader: - kv 10: llama.context_length u32 = 131072
llama_model_loader: - kv 11: llama.embedding_length u32 = 3072
llama_model_loader: - kv 12: llama.feed_forward_length u32 = 8192
llama_model_loader: - kv 13: llama.attention.head_count u32 = 24
llama_model_loader: - kv 14: llama.attention.head_count_kv u32 = 8
llama_model_loader: - kv 15: llama.rope.freq_base f32 = 500000.000000
llama_model_loader: - kv 16: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 17: llama.attention.key_length u32 = 128
llama_model_loader: - kv 18: llama.attention.value_length u32 = 128
llama_model_loader: - kv 19: general.file_type u32 = 15
llama_model_loader: - kv 20: llama.vocab_size u32 = 128256
llama_model_loader: - kv 21: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 22: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 23: tokenizer.ggml.pre str = llama-bpe
llama_model_loader: - kv 24: tokenizer.ggml.tokens arr[str,128256] = ["!", "\"", "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 25: tokenizer.ggml.token_type arr[i32,128256] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 26: tokenizer.ggml.merges arr[str,280147] = ["Ġ Ġ", "Ġ ĠĠĠ", "ĠĠ ĠĠ", "...
llama_model_loader: - kv 27: tokenizer.ggml.bos_token_id u32 = 128000
llama_model_loader: - kv 28: tokenizer.ggml.eos_token_id u32 = 128009
llama_model_loader: - kv 29: tokenizer.chat_template str = {{- bos_token }}\n{%- if custom_tools ...
llama_model_loader: - kv 30: general.quantization_version u32 = 2
llama_model_loader: - kv 31: quantize.imatrix.file str = /models_out/Llama-3.2-3B-Instruct-GGU...
llama_model_loader: - kv 32: quantize.imatrix.dataset str = /training_dir/calibration_datav3.txt
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 196
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 125
llama_model_loader: - type f32: 58 tensors
llama_model_loader: - type q4_K: 168 tensors
llama_model_loader: - type q6_K: 29 tensors
llm_load_vocab: special tokens cache size = 256
llm_load_vocab: token to piece cache size = 0.7999 MB
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = BPE
llm_load_print_meta: n_vocab = 128256
llm_load_print_meta: n_merges = 280147
llm_load_print_meta: vocab_only = 0
llm_load_print_meta: n_ctx_train = 131072
llm_load_print_meta: n_embd = 3072
llm_load_print_meta: n_layer = 28
llm_load_print_meta: n_head = 24
llm_load_print_meta: n_head_kv = 8
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_swa = 0
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 3
llm_load_print_meta: n_embd_k_gqa = 1024
llm_load_print_meta: n_embd_v_gqa = 1024
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 8192
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 500000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_ctx_orig_yarn = 131072
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: ssm_dt_b_c_rms = 0
llm_load_print_meta: model type = 3B
llm_load_print_meta: model ftype = Q4_K - Medium
llm_load_print_meta: model params = 3.21 B
llm_load_print_meta: model size = 1.87 GiB (5.01 BPW)
llm_load_print_meta: general.name = Llama 3.2 3B Instruct
llm_load_print_meta: BOS token = 128000 '<|begin_of_text|>'
llm_load_print_meta: EOS token = 128009 '<|eot_id|>'
llm_load_print_meta: EOT token = 128009 '<|eot_id|>'
llm_load_print_meta: EOM token = 128008 '<|eom_id|>'
llm_load_print_meta: LF token = 128 'Ä'
llm_load_print_meta: EOG token = 128008 '<|eom_id|>'
llm_load_print_meta: EOG token = 128009 '<|eot_id|>'
llm_load_print_meta: max token length = 256
llm_load_tensors: offloading 28 repeating layers to GPU
llm_load_tensors: offloading output layer to GPU
llm_load_tensors: offloaded 29/29 layers to GPU
llm_load_tensors: CPU_Mapped model buffer size = 308.23 MiB
llm_load_tensors: CUDA0 model buffer size = 1918.35 MiB
...........................................................................
llama_new_context_with_model: n_seq_max = 1
llama_new_context_with_model: n_ctx = 4096
llama_new_context_with_model: n_ctx_per_seq = 4096
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 0
llama_new_context_with_model: freq_base = 500000.0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: n_ctx_per_seq (4096) < n_ctx_train (131072) -- the full capacity of the model will not be utilized
llama_kv_cache_init: kv_size = 4096, offload = 1, type_k = 'f16', type_v = 'f16', n_layer = 28, can_shift = 1
llama_kv_cache_init: CUDA0 KV buffer size = 448.00 MiB
llama_new_context_with_model: KV self size = 448.00 MiB, K (f16): 224.00 MiB, V (f16): 224.00 MiB
llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 256.50 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 14.01 MiB
llama_new_context_with_model: graph nodes = 902
llama_new_context_with_model: graph splits = 2
common_init_from_params: setting dry_penalty_last_n to ctx_size = 4096
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
main: llama threadpool init, n_threads = 4
main: chat template example:
<|start_header_id|>system<|end_header_id|>
You are a helpful assistant<|eot_id|><|start_header_id|>user<|end_header_id|>
Hello<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Hi there<|eot_id|><|start_header_id|>user<|end_header_id|>
How are you?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
system_info: n_threads = 4 (n_threads_batch = 4) / 4 | CUDA : USE_GRAPHS = 1 | PEER_MAX_BATCH_SIZE = 128 | CPU : NEON = 1 | ARM_FMA = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 |
main: interactive mode on.
sampler seed: 2854367793
sampler params:
repeat_last_n = 64, repeat_penalty = 1.000, frequency_penalty = 0.000, presence_penalty = 0.000
dry_multiplier = 0.000, dry_base = 1.750, dry_allowed_length = 2, dry_penalty_last_n = 4096
top_k = 40, top_p = 0.950, min_p = 0.050, xtc_probability = 0.000, xtc_threshold = 0.100, typical_p = 1.000, temp = 0.800
mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000
sampler chain: logits -> logit-bias -> penalties -> dry -> top-k -> typical -> top-p -> min-p -> xtc -> temp-ext -> dist
generate: n_ctx = 4096, n_batch = 2048, n_predict = -1, n_keep = 1
== Running in interactive mode. ==
- Press Ctrl+C to interject at any time.
- Press Return to return control to the AI.
- To return control without starting a new line, end your input with '/'.
- If you want to submit another line, end your input with '\'.
> Llama, tell me what a Nintendo Switch is
The Nintendo Switch is a hybrid video game console developed and published by Nintendo. It was released in 2017 and has since become one of the most popular gaming platforms in the world.
The Switch is designed to be a versatile device that can be used in multiple modes:
1. **Portable mode**: The Switch can be held like a tablet, allowing players to take it anywhere and play games on the go.
2. **Tabletop mode**: The Switch can be placed on a flat surface, detach its Joy-Con controllers, and be used like a television. This mode is ideal for multiplayer games or when playing with a large group.
3. **TV mode**: The Switch can be connected to a television using an HDMI cable, providing a bigger screen and more immersive gaming experience.
The Switch has a robust library of games, including popular titles like Super Mario Odyssey, The Legend of Zelda: Breath of the Wild, Mario Kart 8 Deluxe, and Splatoon 2. It also has a range of indie games, eShop releases, and Nintendo's own franchises.
Some of the key features of the Switch include:
* A 6.2-inch capacitive touchscreen display
* A 32-bit Tegra X1 processor
* 4GB or 32GB of RAM
* A battery life of up to 2.5 to 6 hours, depending on the game and brightness settings
* Support for Joy-Con controllers, which can be attached to the sides of the console or used separately
* Compatibility with Nintendo's Amiibo figures and other accessories
Overall, the Nintendo Switch is a unique and innovative gaming platform that offers a distinct gaming experience, making it a popular choice among gamers of all ages!
> Can a Nintendo Switch run a large language model?
While the Nintendo Switch is a powerful gaming console, its hardware might not be the most suitable for running large language models.
Here are some reasons why:
1. **Processing power**: The Switch's Tegra X1 processor, which is a 32-bit processor, might not be powerful enough to handle the complex computations required for training and running large language models. Language models typically require significant computational resources, especially when it comes to large-scale models like BERT, RoBERTa, or transformer-based models.
2. **Memory**: The Switch has 4GB or 32GB of RAM, which is relatively limited compared to the requirements of large language models. These models often require massive amounts of memory to store their weights and activations, especially when fine-tuning or generating text.
3. **Graphics processing unit (GPU)**: The Switch's GPU is optimized for gaming and not specifically designed for AI computing. This means it might not be able to handle the intense computational tasks required for running large language models.
However, it's not impossible to run a large language model on a Nintendo Switch. Some researchers and developers have explored using the Switch for running smaller, more lightweight language models, such as those based on transformer architectures. In these cases, the Switch's processor and memory can be sufficient to run the model.
If you're interested in running a large language model on a Nintendo Switch, you might consider the following:
1. **Downsample the model**: Use a smaller, more efficient version of the language model to reduce its computational requirements.
2. **Use a more lightweight framework**: Explore alternative frameworks, such as TensorFlow Lite or PyTorch, which are optimized for mobile and embedded devices.
3. **Use a cloud-based service**: Consider using a cloud-based service, such as AWS SageMaker or Google Cloud AI Platform, which can provide more powerful computing resources and scalability.
Keep in mind that running a large language model on a Nintendo Switch will likely require significant optimization, and the results might not be as impressive as running the model on a more powerful device.
Would you like to explore any of these options further?
>
llama_perf_sampler_print: sampling time = 784.87 ms / 445 runs ( 1.76 ms per token, 566.97 tokens per second)
llama_perf_context_print: load time = 57389.43 ms
llama_perf_context_print: prompt eval time = 16092.76 ms / 40 tokens ( 402.32 ms per token, 2.49 tokens per second)
llama_perf_context_print: eval time = 220373.49 ms / 771 runs ( 285.83 ms per token, 3.50 tokens per second)
llama_perf_context_print: total time = 396023.26 ms / 811 tokens
Interrupted by userThat’s right folks, with only mild amounts of hacking we can get modern LLMs ✨ running at a pretty reasonable clip [4 tokens per second] on a Nintendo Switch! Here’s how it works, and what hacks were needed to get there.
Basic Premise
There’s an organization of folks collectively named Switchroot who have done an unbelievable amount of work to make a pleasant and easy-to-use port of Linux4Tegra to the Switch. There are ports of three different Ubuntu versions, Fedora and Android. The Joy-Cons work, there are built in power profiles including overclocking for both CPU and GPU, touchscreen and HDMI out work, auto rotate works, sleep works… Everything works.
Including CUDA. At least, on the original Ubuntu version L4T shipped with, 18.04.
CUDA is a platform for universal GPU acceleration across all Nvidia GPUs. Anything from the lowliest $50 GPU in the back of an old desktop to the most powerful server accelerator card can be programmed using one unified API. That means that, in theory, the code that runs LLM ✨ inference on CUDA will Just Work when compiled to run on the Tegra X1.
Meanwhile, Nvidias competitors are still not capable of getting their compute stack to run well on their highest-end five-figure accelerators, let alone any of their desktop GPUs.
For reference, Nvidia still actively supports desktop Maxwell GPUs, released almost 11 years ago.
At least things are improving. I was able to run an LLM on my new AMD laptop just the other day after lots of compiling experimental forks; better than my past experiences, which are just “give up, it’s broken.”
Of course, there’s a catch– Nvidia dropped support for the Tegra X1 quite some time ago, and we’re left with CUDA version 10.2.
llama.cpp, arguably the most popular project for running LLMs ✨ at home, uses GGML as the core code that actually performs the high-speed matrix multiplication for AI ✨. So all we have to do is backport GGML to CUDA 10.2 and we’ll be all set to run AI on the Switch ✨.
Warning: Gory configuration, patches, and dependencies ahead
This all took about a weekend to figure out. It’s not that bad, there’s just a lot of it, and it’s not all very interesting. I’m just putting it here so others can replicate this process.
We start here:
cmake -B build -DGGML_CUDA=on -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc Problem: Linux4Tegra ships with CUDA 10.0 out of the box. We need CUDA 10.2 so we can have cublasLt, which GGML relies on.
The Switchroot folks have you covered. There’s a quick update procedure on their Discord (yes, I know…) which will get you updated.
Problem: GGML freaks out immediately when using such an old compiler:
CMake Error in src/ggml-cuda/CMakeLists.txt:
Target "ggml-cuda" requires the language dialect "CUDA17" (with compiler
extensions). But the current compiler "NVIDIA" does not support this, or
CMake does not know the flags to enable it.I found these CMake flags lying around that make the error go away.
cmake -B build -DGGML_CUDA=on -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc -DCMAKE_CUDA_STANDARD=14 -DCMAKE_CUDA_STANDARD_REQUIRED=true Problem: Tegra X1 has its own CUDA architecture code (53), separate from desktop Maxwell (52). Specify this:
cmake -B build -DGGML_CUDA=on -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc -DCMAKE_CUDA_ARCHITECTURES=53 -DCMAKE_CUDA_STANDARD=14 -DCMAKE_CUDA_STANDARD_REQUIRED=true Problem: GGML is currently bugged when compiling for ARM. Add more CMake flags to make it go away.
cmake -B build -DGGML_CUDA=on -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc -DCMAKE_CUDA_ARCHITECTURES=53 -DCMAKE_CUDA_STANDARD=14 -DCMAKE_CUDA_STANDARD_REQUIRED=true -DGGML_NATIVE=off -DGGML_CPU_ARM_ARCH=armv8-aProblem: Ubuntu 18.04 ships with GCC 7. CUDA 10.2 will not compile on anything newer than GCC 8.5. We need a new version of GCC, which adds support for compiler intrinsics used for GGMLs ARM64 backend. GGML will not compile without these.
So basically, you have to backport this patch to GCC 8.5 and build GCC from source yourself. You can cherry-pick commit 84d713f6f45bef44b8bea84b02caa8a165bff1b5, it applies cleanly to the 8.5 release tag. Then just wait a couple hours for the Switch’s anemic CPU to compile a compiler. (Or git gud and figure out how to cross-compile a native compiler. I am not gud enough to figure that out.)
Once that’s applied, you can continue building GGML with your shiny new-old compiler. Don’t forget to set up update-alternatives so CUDA looks at GCC and is happy. Our final CMake flags are:
cmake -B build -DGGML_CUDA=on -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc -DCMAKE_CUDA_ARCHITECTURES=53 -DCMAKE_CUDA_STANDARD=14 -DCMAKE_CUDA_STANDARD_REQUIRED=true -DGGML_NATIVE=off -DGGML_CPU_ARM_ARCH=armv8-a -DCMAKE_C_COMPILER=/home/qwe/gcc-install/home/qwe/gcc/bin/gcc -DCMAKE_CXX_COMPILER=/home/qwe/gcc-install/home/qwe/gcc/bin/g++Problem: We’re making headway. Now we’re getting to actual compiler errors from actual missing features.
GGML throws this:
/home/qwe/ggml/src/ggml-cuda/common.cuh(348): error: A __device__ variable cannot be marked constexprThat’s a CUDA C++17 feature. CUDA 10.2 doesn’t support C++17. The fix is easy, thankfully, just remove the constexpr.
/home/qwe/ggml/src/ggml-cuda/fattn-common.cuh(532): error: identifier "__builtin_assume" is undefinedThis is splattered around in a few places . It’s just a compiler hint for performance, you can just comment it out.
Problem: Compilation succeeds, but linker errors are getting thrown out the wazoo:
../src/libggml.so: undefined reference to `std::filesystem::__cxx11::filesystem_error::_M_gen_what()'
../src/libggml.so: undefined reference to `vtable for std::filesystem::__cxx11::filesystem_error'
../src/libggml.so: undefined reference to `std::filesystem::__cxx11::directory_iterator::operator*() const'
../src/libggml.so: undefined reference to `typeinfo for std::filesystem::__cxx11::filesystem_error'
../src/libggml.so: undefined reference to `std::filesystem::__cxx11::path::_M_find_extension() const'
../src/libggml.so: undefined reference to `std::filesystem::__cxx11::filesystem_error::~filesystem_error()'
../src/libggml.so: undefined reference to `std::filesystem::status(std::filesystem::__cxx11::path const&)'
../src/libggml.so: undefined reference to `std::filesystem::__cxx11::path::_M_split_cmpts()'
../src/libggml.so: undefined reference to `std::filesystem::__cxx11::directory_iterator::operator++()'
../src/libggml.so: undefined reference to `std::filesystem::__cxx11::directory_iterator::directory_iterator(std::filesystem::__cxx11::path const&, std::filesystem::directory_options, std::error_code*)'This one was a bit of a stumper. I wound up spending a couple hours trying to figure it out.
I’m still not entirely sure what’s wrong, but I think GCC 8.5, being from an era where C++17 support was still new, doesn’t correctly link shared libraries to std::filesystem. So it throws errors whenever you try to link it into a final binary, since those symbols are left unresolved until final linkage, and then fail to link.
You can add some linker commands to grab GCC by the lapels and say “link this crap, punk” in ggml/CMakeLists.txt.
diff --git a/CMakeLists.txt b/CMakeLists.txt
index 3935065..3376657 100644
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -246,6 +246,8 @@ set(GGML_PUBLIC_HEADERS
include/ggml-vulkan.h)
set_target_properties(ggml PROPERTIES PUBLIC_HEADER "${GGML_PUBLIC_HEADERS}")
+target_link_libraries(ggml PRIVATE stdc++fs)
+add_link_options(-Wl,--copy-dt-needed-entries)
#if (GGML_METAL)
# set_target_properties(ggml PROPERTIES RESOURCE "${CMAKE_CURRENT_SOURCE_DIR}/src/ggml-metal.metal")
#endif()
@@ -260,3 +262,9 @@ if (GGML_STANDALONE)
install(FILES ${CMAKE_CURRENT_BINARY_DIR}/ggml.pc
DESTINATION share/pkgconfig)
endif()I don’t know why these precise commands do the trick, but managed to scrape them together from hours of searching.
We now have a working build!!
We’re so close… llama.cpp can load a large AI model ✨ and write text! I’m loading Llama-3.2-3B-Instruct-Q4_K_M.
Logs of llama.cpp loading
qwe@localhost:~/llama.cpp/build/bin$ ./llama-cli -m ~/Llama-3.2-3B-Instruct-Q4_K_M.gguf -ngl 100 -cnv --chat-template llama3
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA Tegra X1, compute capability 5.3, VMM: no
register_backend: registered backend CUDA (1 devices)
register_device: registered device CUDA0 (NVIDIA Tegra X1)
register_backend: registered backend CPU (1 devices)
register_device: registered device CPU (ARMv8 Processor rev 1 (v8l))
build: 4418 (b56f079e) with gcc (GCC) 8.5.0 for aarch64-unknown-linux-gnu (debug)
main: llama backend init
main: load the model and apply lora adapter, if any
llama_load_model_from_file: using device CUDA0 (NVIDIA Tegra X1) - 2007 MiB free
llama_model_loader: loaded meta data with 35 key-value pairs and 255 tensors from /home/qwe/Llama-3.2-3B-Instruct-Q4_K_M.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Llama 3.2 3B Instruct
llama_model_loader: - kv 3: general.finetune str = Instruct
llama_model_loader: - kv 4: general.basename str = Llama-3.2
llama_model_loader: - kv 5: general.size_label str = 3B
llama_model_loader: - kv 6: general.license str = llama3.2
llama_model_loader: - kv 7: general.tags arr[str,6] = ["facebook", "meta", "pytorch", "llam...
llama_model_loader: - kv 8: general.languages arr[str,8] = ["en", "de", "fr", "it", "pt", "hi", ...
llama_model_loader: - kv 9: llama.block_count u32 = 28
llama_model_loader: - kv 10: llama.context_length u32 = 131072
llama_model_loader: - kv 11: llama.embedding_length u32 = 3072
llama_model_loader: - kv 12: llama.feed_forward_length u32 = 8192
llama_model_loader: - kv 13: llama.attention.head_count u32 = 24
llama_model_loader: - kv 14: llama.attention.head_count_kv u32 = 8
llama_model_loader: - kv 15: llama.rope.freq_base f32 = 500000.000000
llama_model_loader: - kv 16: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 17: llama.attention.key_length u32 = 128
llama_model_loader: - kv 18: llama.attention.value_length u32 = 128
llama_model_loader: - kv 19: general.file_type u32 = 15
llama_model_loader: - kv 20: llama.vocab_size u32 = 128256
llama_model_loader: - kv 21: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 22: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 23: tokenizer.ggml.pre str = llama-bpe
llama_model_loader: - kv 24: tokenizer.ggml.tokens arr[str,128256] = ["!", "\"", "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 25: tokenizer.ggml.token_type arr[i32,128256] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 26: tokenizer.ggml.merges arr[str,280147] = ["Ġ Ġ", "Ġ ĠĠĠ", "ĠĠ ĠĠ", "...
llama_model_loader: - kv 27: tokenizer.ggml.bos_token_id u32 = 128000
llama_model_loader: - kv 28: tokenizer.ggml.eos_token_id u32 = 128009
llama_model_loader: - kv 29: tokenizer.chat_template str = {{- bos_token }}\n{%- if custom_tools ...
llama_model_loader: - kv 30: general.quantization_version u32 = 2
llama_model_loader: - kv 31: quantize.imatrix.file str = /models_out/Llama-3.2-3B-Instruct-GGU...
llama_model_loader: - kv 32: quantize.imatrix.dataset str = /training_dir/calibration_datav3.txt
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 196
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 125
llama_model_loader: - type f32: 58 tensors
llama_model_loader: - type q4_K: 168 tensors
llama_model_loader: - type q6_K: 29 tensors
llm_load_vocab: special tokens cache size = 256
llm_load_vocab: token to piece cache size = 0.7999 MB
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = BPE
llm_load_print_meta: n_vocab = 128256
llm_load_print_meta: n_merges = 280147
llm_load_print_meta: vocab_only = 0
llm_load_print_meta: n_ctx_train = 131072
llm_load_print_meta: n_embd = 3072
llm_load_print_meta: n_layer = 28
llm_load_print_meta: n_head = 24
llm_load_print_meta: n_head_kv = 8
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_swa = 0
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 3
llm_load_print_meta: n_embd_k_gqa = 1024
llm_load_print_meta: n_embd_v_gqa = 1024
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 8192
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 500000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_ctx_orig_yarn = 131072
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: ssm_dt_b_c_rms = 0
llm_load_print_meta: model type = 3B
llm_load_print_meta: model ftype = Q4_K - Medium
llm_load_print_meta: model params = 3.21 B
llm_load_print_meta: model size = 1.87 GiB (5.01 BPW)
llm_load_print_meta: general.name = Llama 3.2 3B Instruct
llm_load_print_meta: BOS token = 128000 '<|begin_of_text|>'
llm_load_print_meta: EOS token = 128009 '<|eot_id|>'
llm_load_print_meta: EOT token = 128009 '<|eot_id|>'
llm_load_print_meta: EOM token = 128008 '<|eom_id|>'
llm_load_print_meta: LF token = 128 'Ä'
llm_load_print_meta: EOG token = 128008 '<|eom_id|>'
llm_load_print_meta: EOG token = 128009 '<|eot_id|>'
llm_load_print_meta: max token length = 256
llm_load_tensors: offloading 28 repeating layers to GPU
llm_load_tensors: offloading output layer to GPU
llm_load_tensors: offloaded 29/29 layers to GPU
llm_load_tensors: CPU_Mapped model buffer size = 308.23 MiB
llm_load_tensors: CUDA0 model buffer size = 1918.35 MiB
...........................................................................
llama_new_context_with_model: n_seq_max = 1
llama_new_context_with_model: n_ctx = 4096
llama_new_context_with_model: n_ctx_per_seq = 4096
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 0
llama_new_context_with_model: freq_base = 500000.0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: n_ctx_per_seq (4096) < n_ctx_train (131072) -- the full capacity of the model will not be utilized
llama_kv_cache_init: kv_size = 4096, offload = 1, type_k = 'f16', type_v = 'f16', n_layer = 28, can_shift = 1
llama_kv_cache_init: CUDA0 KV buffer size = 448.00 MiB
llama_new_context_with_model: KV self size = 448.00 MiB, K (f16): 224.00 MiB, V (f16): 224.00 MiB
llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 256.50 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 14.01 MiB
llama_new_context_with_model: graph nodes = 902
llama_new_context_with_model: graph splits = 2
common_init_from_params: setting dry_penalty_last_n to ctx_size = 4096
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
main: llama threadpool init, n_threads = 4
main: chat template example:
<|start_header_id|>system<|end_header_id|>
You are a helpful assistant<|eot_id|><|start_header_id|>user<|end_header_id|>
Hello<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Hi there<|eot_id|><|start_header_id|>user<|end_header_id|>
How are you?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
system_info: n_threads = 4 (n_threads_batch = 4) / 4 | CUDA : USE_GRAPHS = 1 | PEER_MAX_BATCH_SIZE = 128 | CPU : NEON = 1 | ARM_FMA = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 |
main: interactive mode on.
sampler seed: 2791425704
sampler params:
repeat_last_n = 64, repeat_penalty = 1.000, frequency_penalty = 0.000, presence_penalty = 0.000
dry_multiplier = 0.000, dry_base = 1.750, dry_allowed_length = 2, dry_penalty_last_n = 4096
top_k = 40, top_p = 0.950, min_p = 0.050, xtc_probability = 0.000, xtc_threshold = 0.100, typical_p = 1.000, temp = 0.800
mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000
sampler chain: logits -> logit-bias -> penalties -> dry -> top-k -> typical -> top-p -> min-p -> xtc -> temp-ext -> dist
generate: n_ctx = 4096, n_batch = 2048, n_predict = -1, n_keep = 1
== Running in interactive mode. ==
- Press Ctrl+C to interject at any time.
- Press Return to return control to the AI.
- To return control without starting a new line, end your input with '/'.
- If you want to submit another line, end your input with '\'.
> But what’s this? After I type a prompt, it crashes…
> What's up?
Killed
qwe@localhost:~/llama.cpp/build/bin$ Insidious, deep bug somewhere in the depths that I’ll never find?
Thankfully, no. The system is just running too low on memory and the OOM killer assassinates the process.
It turns out that GDM3 and Unity, the default display manager and desktop environment, are way too RAM heavy to give a 3B model the 3 gigabtes of breathing room (out of 4GB total) it needs. Llama 3.2 1B runs fine, and if you take out all graphical stuff with sudo systemctl isolate multi-user.target the 3B model will work fine over SSH. But that’s boring, so we’ll install lightdm and LXDE to get a working desktop environment. There’s a quick and easy script from Switchroot that’ll take care of LXDE:
bash <( curl https://raw.githubusercontent.com/cobalt2727/L4T-Megascript/master/helper.sh ) "scripts/desktop_environments/lxde.sh"And lightdm is already installed, just set it as the default with sudo dpkg-reconfigure lightdm and reboot.
You can make the OOM killer less trigger happy, and Ubuntu less overly swap-happy, like so:
echo -1000 | sudo tee /proc/$PID_OF_LLAMACPP/oom_score_adj
sudo sysctl vm.swappiness=10All Done!
The world is now our oyster with the newfound power of running AI on the Nintendo Switch ✨. What unlimited power will this souped-up console provide? What secrets of the universe will it unveil?
Well, while I was dealing with the low-RAM issue, I asked it to give me some advice on how to make the OOM killer play nice. It spat out some hallucinations, but they were close enough to send me in the right direction with a quick search.
My conversation with it can be found by clicking here
> Llama, we have a problem. You are being run in a resource-constrained environment. I have stopped almost all other processes to make room for you to run. If I attempt to restart a graphical environment, which requires a lot of memory, your process is terminated. Tell me how to prevent the Linux OOM killer from doing this to your process.
When running in a resource-constrained environment, the Linux OOM (Out of Memory) killer can be a major issue. Here are a few strategies to help prevent the OOM killer from terminating my process:
### 1. Increase the OOM Score
The OOM killer can be configured to prioritize processes based on their OOM score, which is a value assigned to each process based on its memory usage and other factors. To increase my OOM score, you can use the `echo` command to set my priority:
```bash
echo 0 | tee /proc/sys/vm/oom_score_adjust
```
This will increase my OOM score, making it less likely to be terminated by the OOM killer.
### 2. Use `cgroups` to limit my memory usage
By using `cgroups` (Control Groups), we can limit the amount of memory that my process can use. Here's how to do it:
```bash
echo 100000 | tee /sys/fs/cgroup/memory/limit
```
This sets the memory limit to 100,000 bytes. You can adjust this value to a lower limit if you want to be more conservative with my memory usage.
### 3. Disable `lockdown` and `swap` limitations
The `lockdown` option prevents processes from using swap memory, while the `swap` option limits the amount of swap memory that can be used. To disable these options, run the following commands:
```bash
echo 0 | tee /proc/sys/vm/lockdown
echo 0 | tee /proc/sys/vm/swappiness
```
The `lockdown` option is now set to 0, and the `swap` option is set to 0, allowing me to use more memory.
### 4. Run me as `nice` or `realtime`
To prioritize my process, you can run me with the `nice` or `realtime` scheduling class. Here's how to do it:
```bash
renice -n -10 -p $PID | tee /proc/$PID/sched_flags
```
or
```bash
taskset -a -c 0-3 -p $PID | tee /proc/$PID/sched_flags
```
This sets my priority to the highest level ( `-10` for `nice` or `0-3` for `realtime`).
### 5. Monitor and adjust the OOM settings
To monitor the OOM settings, you can use the `sysctl` command to view the current settings:
```bash
sysctl -a | grep oom
```
You can adjust these settings as needed to balance memory usage and the risk of the OOM killer terminating my process.
These are some of the strategies you can use to prevent the Linux OOM killer from terminating my process. You may need to experiment with different combinations of these settings to find the right balance for your specific use case.
> Can you elaborate on your first idea?
The first idea I mentioned was to increase the OOM score of my process using the `echo` command. This is done by writing the value `0` to a specific file in the `/proc/sys/vm/` directory.
The OOM score is a value that is assigned to each process based on its memory usage and other factors. A higher OOM score means that the process is more likely to be prioritized by the OOM killer when memory is low. Conversely, a lower OOM score means that the process is less likely to be prioritized.
By setting the OOM score to `0`, we are effectively making my process more resistant to being terminated by the OOM killer. This is because a low OOM score means that the process is not considered high-priority, and therefore will not be terminated unless absolutely necessary.
Here's a breakdown of the OOM scores and their meanings:
* `0`: Low priority, process will be terminated if memory is low.
* `10`: Low priority, process will be terminated if memory is low, but will be prioritized if essential processes are terminated.
* `20`: Medium priority, process will be terminated if memory is low, but will be prioritized if essential processes are terminated.
* `30`: High priority, process will be terminated if memory is low, but will be prioritized if essential processes are terminated.
* `40`: High priority, process will be terminated if memory is low, but will be prioritized if essential processes are terminated.
* `50`: Very high priority, process will be terminated if memory is low, but will be prioritized if essential processes are terminated.
By setting the OOM score to `0`, we are effectively choosing the "very high priority" option, which means that my process will be prioritized over all other processes when memory is low.
It's worth noting that setting the OOM score to `0` can have unintended consequences, such as allowing my process to consume excessive memory resources. Therefore, it's generally recommended to set the OOM score to a value that balances resource usage and priority.
Alternatively, you can use the `vm.set_oom_score_adj` sysctl to set the OOM score:
```bash
echo 0 | tee /proc/sys/vm/set_oom_score_adj
```
This sets the OOM score to `-10`, which is equivalent to setting it to `0`.
> Why would it be /proc/sys/vm if the value is per-process?
You are correct, the OOM score is per-process, and the file `/proc/sys/vm/oom_score_adjust` is a global setting that affects all processes.
The `oom_score_adjust` value is used to adjust the OOM score of a process, but it's not a per-process setting. Instead, it's a global setting that can be used to adjust the OOM score of the entire system.
If you want to set a specific OOM score for a process, you can use the `renice` command, which allows you to adjust the priority of a process. The `renice` command takes the `-n` option followed by the new priority value. For example:
```bash
renice -n -10 -p $PID
```
This sets the priority of the process with PID `$PID` to `-10`, which is a high priority value. The OOM killer will prioritize this process over other processes when memory is low.
Alternatively, you can use the `taskset` command to set the CPU affinity of a process, which can also be used to prioritize a process:
```bash
taskset -a -c 0-3 -p $PID
```
This sets the CPU affinity of the process with PID `$PID` to the first four CPUs, which can be used to prioritize the process.
In summary, the `oom_score_adjust` file is a global setting that affects all processes, while the `renice` and `taskset` commands can be used to adjust the priority of a specific process.…But in the end, I think I’ll reboot it to the stock OS and go back to playing games on it.
After all, there are more epic Splatoon plays to be made.
Credits
Although this was a one-weekend hackjob, it would be remiss to not cite the multiple man-years of heruclean reverse engineering efforts that made it possible.
First and foremost, I’d like to thank Nvidia for providing the Tegra X1, providing CUDA, and fucking up on the Tegra X1 bootrom, opening the door for Switch hacking in the first place.
Thanks to EXO Lab’s llama98 demo for inspiring this shitpost.
The Switchroot team has put a tremendous amount of labor into making Linux on the Switch as friendly and easy to use as possible. Special credits to CTCaer who has contributed massive amounts to Switchroot and the scene as a whole with other projects like hekate.
The contributors to GGML and llama.cpp were invaluable to this project, of course.
Thanks to the Atmosphere-NX project and ReSwitched for much of the initial RE work into the Switch.
And finally, I’d like to give a shoutout to all the writers, artists and musicians whose works were stolen for the purposes of training these models.
Leave a Reply